11 Principles for building and scaling feature flag systems
Feature flags, sometimes called feature toggles or feature switches, are a software development technique that allows engineering teams to decouple the release of new functionality from software deployments. With feature flags, developers can turn specific features or code segments on or off at runtime, without the need for a code deployment or rollback. Organizations who adopt feature flags see improvements in all key operational metrics for DevOps: Lead time to changes, mean-time-to-recovery, deployment frequency, and change failure rate.
There are 11 principles for building a large-scale feature flag system. These principles have their roots in distributed systems architecture and pay particular attention to security, privacy, and scale that is required by most enterprise systems. If you follow these principles, your feature flag system is less likely to break under load and will be easier to evolve and maintain.
These principles are:
- 1. Enable run-time control. Control flags dynamically, not using config files.
- 2. Never expose PII. Follow the principle of least privilege.
- 3. Evaluate flags as close to the user as possible. Reduce latency.
- 4. Scale Horizontally. Decouple reading and writing flags.
- 5. Limit payloads. Feature flag payload should be as small as possible.
- 6. Design for failure. Favor availability over consistency.
- 7. Make feature flags short-lived. Do not confuse flags with application configuration.
- 8. Use unique names across all applications. Enforce naming conventions.
- 9. Choose open by default. Democratize feature flag access.
- 10. Do no harm. Prioritize consistent user experience.
- 11. Enable traceability. Make it easy to understand flag evaluation.
Background
Feature flags have become a central part of the DevOps toolbox along with Git, CI/CD and microservices. You can write modern software without all of these things, but it sure is a lot harder, and a lot less fun.
And just like the wrong Git repo design can cause interminable headaches, getting the details wrong when first building a feature flag system can be very costly.
This set of principles for building a large-scale feature management platform is the result of thousands of hours of work building and scaling Unleash, an open-source feature management solution used by thousands of organizations.
Before Unleash was a community and a company, it was an internal project, started by one dev, for one company. As the community behind Unleash grew, patterns and anti-patterns of large-scale feature flag systems emerged. Our community quickly discovered that these are important principles for anyone who wanted to avoid spending weekends debugging the production system that is supposed to make debugging in production easier.
“Large scale” means the ability to support millions of flags served to end-users with minimal latency or impact on application uptime or performance. That is the type of system most large enterprises are building today and the type of feature flag system that this guide focuses on.
Our motivation for writing these principles is to share what we’ve learned building a large-scale feature flag solution with other architects and engineers solving similar challenges. Unleash is open-source, and so are these principles. Have something to contribute? Open a PR or discussion on our Github.
1. Enable run-time control. Control flags dynamically, not using config files.
A scalable feature management system evaluates flags at runtime. Flags are dynamic, not static. If you need to restart your application to turn on a flag, you are using configuration, not feature flags.
A large-scale feature flag system that enables runtime control should have at minimum the following components:
1. Feature Flag Control Service: Use a centralized feature flag service that acts as the control plane for your feature flags. This service will handle flag configuration. The scope of this service should reflect the boundaries of your organization.
Independent business units or product lines should potentially have their own instances, while business units or product lines that work closely together should most likely use the same instance in order to facilitate collaboration. This will always be a contextual decision based on your organization and how you organize the work, but keep in mind that you’d like to keep the management of the flags as simple as possible to avoid the complexity of cross-instance synchronization of feature flag configuration.
2. Database or Data Store: Use a robust and scalable database or data store to store feature flag configurations. Popular choices include SQL or NoSQL databases or key-value stores. Ensure that this store is highly available and reliable.
3. API Layer: Develop an API layer that exposes endpoints for your application to interact with the Feature Flag Control Service. This API should allow your application to request feature flag configurations.
4. Feature Flag SDK: Build or integrate a feature flag SDK into your application. This SDK should provide an easy-to-use interface for fetching flag configurations and evaluating feature flags at runtime. When evaluating feature flags in your application, the call to the SDK should query the local cache, and the SDK should ask the central service for updates in the background.
Build SDK bindings for each relevant language in your organization. Make sure that the SDKs uphold a standard contract governed by a set of feature flag client specifications that documents what functionality each SDK should support.
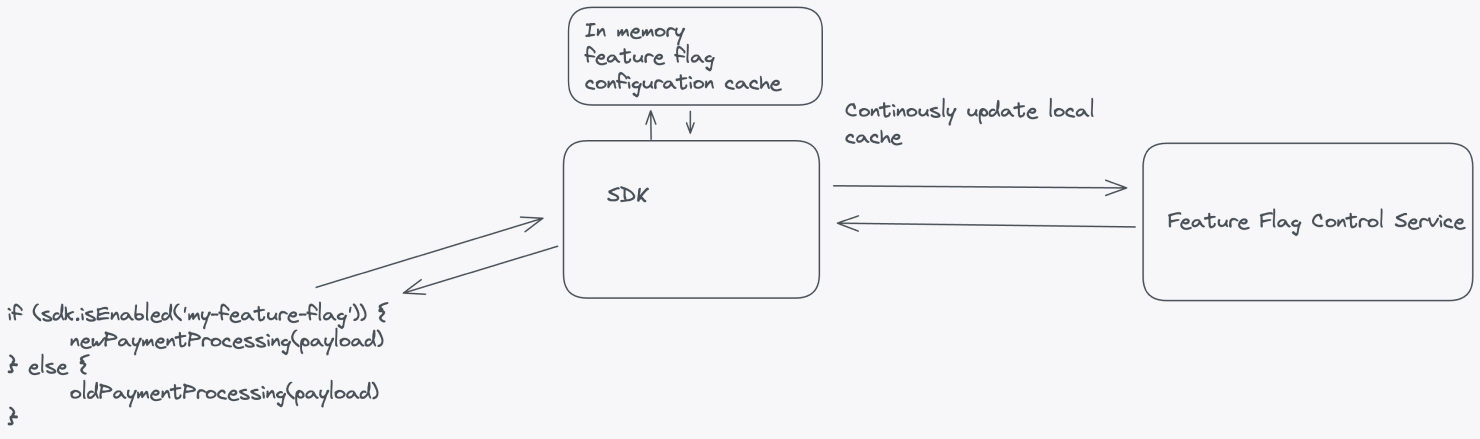
5. Continuously Updated: Implement update mechanisms in your application so that changes to feature flag configurations are reflected without requiring application restarts or redeployments. The SDK should handle subscriptions or polling to the feature flag service for updates.
2. Never expose PII. Follow the principle of least privilege.
To keep things simple, you may be tempted to evaluate the feature flags in your Feature Flag Control Service. Don’t. Your Feature Flag Control Service should only handle the configuration for your feature flags and pass this configuration down to SDKs connecting from your applications.
The primary rationale behind this practice is that feature flags often require contextual data for accurate evaluation. This may include user IDs, email addresses, or geographical locations that influence whether a flag should be toggled on or off. Safeguarding this sensitive information from external exposure is paramount. This information may include Personally Identifiable Information (PII), which must remain confined within the boundaries of your application, following the data security principle of least privilege (PoLP).
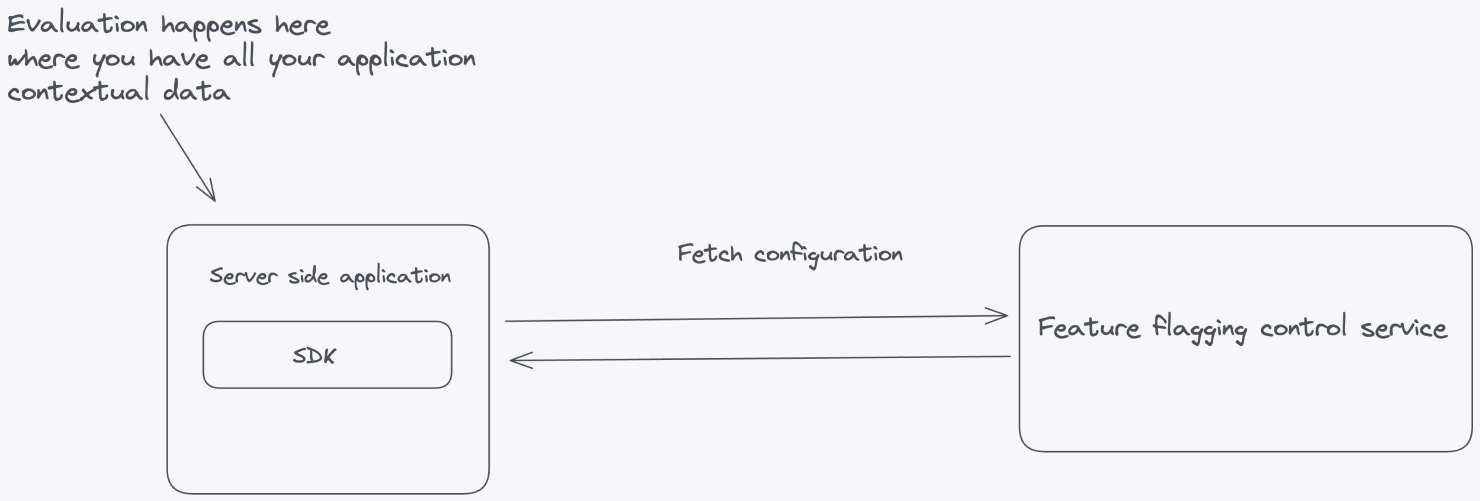
For client-side applications where the code resides on the user's machine, such as in the browser or on mobile devices, you’ll want to take a different approach. You can’t evaluate on the client side because it raises significant security concerns by exposing potentially sensitive information such as API keys, flag data, and flag configurations. Placing these critical elements on the client side increases the risk of unauthorized access, tampering, or data breaches.
Instead of performing client-side evaluation, a more secure and maintainable approach is to conduct feature flag evaluation within a self-hosted environment. Doing so can safeguard sensitive elements like API keys and flag configurations from potential client-side exposure. This strategy involves a server-side evaluation of feature flags, where the server makes decisions based on user and application parameters and then securely passes down the evaluated results to the frontend without any configuration leaking.
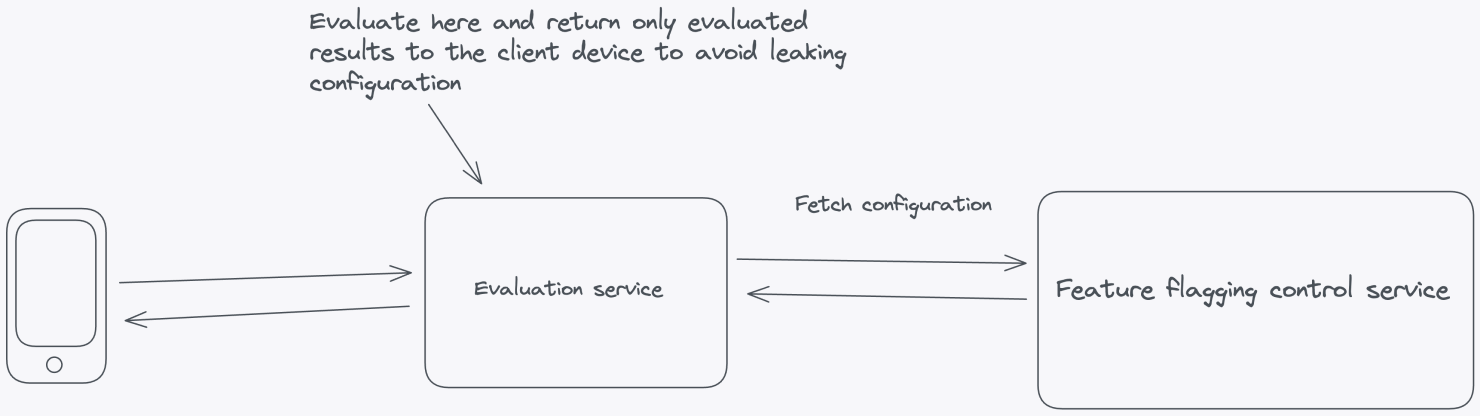
Here’s how you can architect your solution to minimize PII or configuration leakage:
- Server-Side Components:
In Principle 1, we proposed a set of architectural principles and components to set up a Feature Flag Control Service. The same architecture patterns apply here, with additional suggestions for achieving local evaluation. Refer to Principle 1 for patterns to set up a feature flagging service.
Feature Flag Evaluation Service: If you need to use feature flags on the client side, where code is delivered to users' devices, you’ll need an evaluation server that can evaluate feature flags and pass evaluated results down to the SDK in the client application.
- SDKs:
SDKs will make it more comfortable to work with feature flags. Depending on the context of your infrastructure, you need different types of SDKs to talk to your feature flagging service. For the server side, you’ll need SDKs that can talk directly to the feature flagging service and fetch the configuration.
The server-side SDKs should implement logic to evaluate feature flags based on the configuration received from the Feature Flag Control Service and the application-specific context. Local evaluation ensures that decisions are made quickly without relying on network roundtrips.
For client-side feature flags, you’ll need a different type of SDK. These SDKs will send the context to the Feature Flag Evaluation Service and receive the evaluated results. These results should be stored in memory and used when doing a feature flag lookup in the client-side application. By keeping the evaluated results for a specific context in memory in the client-side application, you avoid network roundtrips every time your application needs to check the status of a feature flag. It achieves the same level of performance as a server-side SDK, but the content stored in memory is different and limited to evaluated results on the client.
The benefits of this approach include:
Privacy Protection:
a. Data Minimization: By evaluating feature flags in this way, you minimize the amount of data that needs to be sent to the Feature Flag Control Service. This can be crucial for protecting user privacy, as less user-specific data is transmitted over the network.
b. Reduced Data Exposure: Sensitive information about your users or application's behavior is less likely to be exposed to potential security threats. Data breaches or leaks can be mitigated by limiting the transmission of sensitive data.
3. Evaluate flags as close to the user as possible. Reduce latency.
Feature flags should be evaluated as close to your users as possible, and the evaluation should always happen server side as discussed in Principle 2. In addition to security and privacy benefits, performing evaluation as close as possible to your users has multiple benefits:
Performance Efficiency:
a. Reduced Latency: Network roundtrips introduce latency, which can slow down your application's response time. Local evaluation eliminates the need for these roundtrips, resulting in faster feature flag decisions. Users will experience a more responsive application, which can be critical for maintaining a positive user experience.
b. Offline Functionality: Applications often need to function offline or in low-connectivity environments. Local evaluation ensures that feature flags can still be used and decisions can be made without relying on a network connection. This is especially important for mobile apps or services in remote locations.
Cost Savings:
a. Reduced Bandwidth Costs: Local evaluation reduces the amount of data transferred between your application and the feature flag service. This can lead to significant cost savings, particularly if you have a large user base or high traffic volume.
Offline Development and Testing:
a. Development and Testing: Local evaluation is crucial for local development and testing environments where a network connection to the feature flag service might not be readily available. Developers can work on feature flag-related code without needing constant access to the service, streamlining the development process.
Resilience:
a. Service Outages: If the feature flag service experiences downtime or outages, local evaluation allows your application to continue functioning without interruptions. This is important for maintaining service reliability and ensuring your application remains available even when the service is down.
In summary, this principle emphasizes the importance of optimizing performance while protecting end-user privacy by evaluating feature flags as close to the end user as possible. Done right, this also leads to a highly available feature flag system that scales with your applications.
4. Scale Horizontally. Decouple reading and writing flags.
Separating the reading and writing of feature flags into distinct APIs is a critical architectural decision for building a scalable and efficient feature flag system, particularly when considering horizontal scaling. This separation provides several benefits:
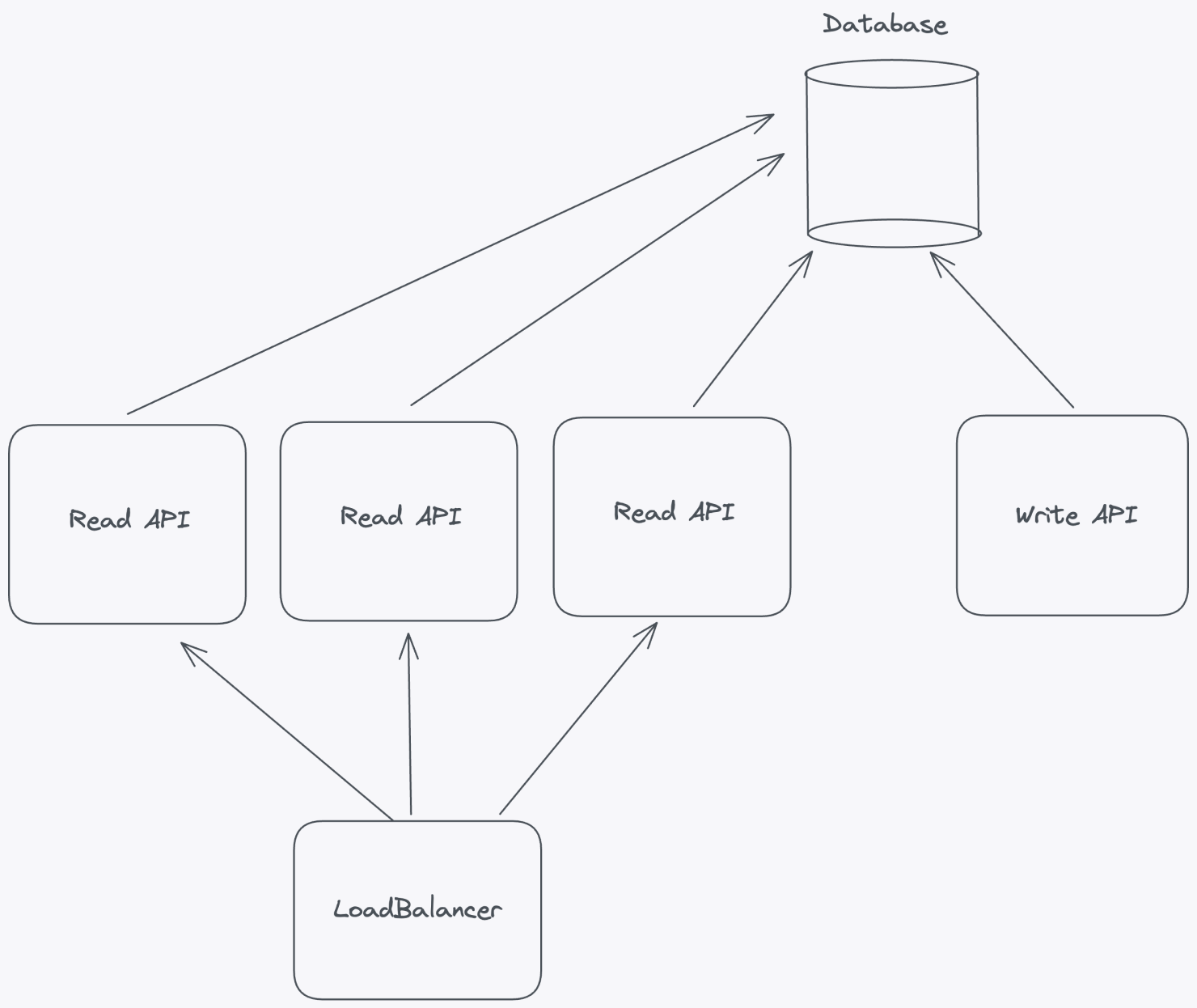
Horizontal Scaling:
- By separating read and write APIs, you can horizontally scale each component independently. This enables you to add more servers or containers to handle increased traffic for reading feature flags, writing updates, or both, depending on the demand.
Caching Efficiency:
- Feature flag systems often rely on caching to improve response times for flag evaluations. Separating read and write APIs allows you to optimize caching strategies independently. For example, you can cache read operations more aggressively to minimize latency during flag evaluations while still ensuring that write operations maintain consistency across the system.
Granular Access Control:
- Separation of read and write APIs simplifies access control and permissions management. You can apply different security measures and access controls to the two APIs. This helps ensure that only authorized users or systems can modify feature flags, reducing the risk of accidental or unauthorized changes.
Better Monitoring and Troubleshooting:
- Monitoring and troubleshooting become more straightforward when read and write operations are separated. It's easier to track and analyze the performance of each API independently. When issues arise, you can isolate the source of the problem more quickly and apply targeted fixes or optimizations.
Flexibility and Maintenance:
- Separation of concerns makes your system more flexible and maintainable. Changes or updates to one API won't directly impact the other, reducing the risk of unintended consequences. This separation allows development teams to work on each API separately, facilitating parallel development and deployment cycles.
Load Balancing:
- Load balancing strategies can be tailored to the specific needs of the read and write APIs. You can distribute traffic and resources accordingly to optimize performance and ensure that neither API becomes a bottleneck under heavy loads.
5. Limit payloads. Feature flag payload should be as small as possible.
Minimizing the size of feature flag payloads is a critical aspect of maintaining the efficiency and performance of a feature flag system. The configuration of your feature flags can vary in size depending on the complexity of your targeting rules. For instance, if you have a targeting engine that determines whether a feature flag should be active or inactive based on individual user IDs, you might be tempted to include all these user IDs within the configuration payload. While this approach may work fine for a small user base, it can become unwieldy when dealing with a large number of users.
If you find yourself facing this challenge, your instinct might be to store this extensive user information directly in the feature flagging system. However, this can also run into scaling problems. A more efficient approach is to categorize these users into logical groupings at a different layer and then use these group identifiers when you evaluate flags within your feature flagging system. For example, you can group users based on their subscription plan or geographical location. Find a suitable parameter for grouping users, and employ those group parameters as targeting rules in your feature flagging solution.
Imposing limitations on payloads is crucial for scaling a feature flag system:
Reduced Network Load:
- Large payloads, especially for feature flag evaluations, can lead to increased network traffic between the application and the feature flagging service. This can overwhelm the network and cause bottlenecks, leading to slow response times and degraded system performance. Limiting payloads helps reduce the amount of data transferred over the network, alleviating this burden. Even small numbers become large when multiplied by millions.
Faster Evaluation:
- Smaller payloads reduce latency which means quicker transmission and evaluation. Speed is essential when evaluating feature flags, especially for real-time decisions that impact user experiences. Limiting payloads ensures evaluations occur faster, allowing your application to respond promptly to feature flag changes.
Improved Memory Efficiency:
- Feature flagging systems often store flag configurations in memory for quick access during runtime. Larger payloads consume more memory, potentially causing memory exhaustion and system crashes. By limiting payloads, you ensure that the system remains memory-efficient, reducing the risk of resource-related issues.
Scalability:
- Scalability is a critical concern for modern applications, especially those experiencing rapid growth. Feature flagging solutions need to scale horizontally to accommodate increased workloads. Smaller payloads require fewer resources for processing, making it easier to scale your system horizontally.
Lower Infrastructure Costs:
- When payloads are limited, the infrastructure required to support the feature flagging system can be smaller and less costly. This saves on infrastructure expenses and simplifies the management and maintenance of the system.
Reliability:
- A feature flagging system that consistently delivers small, manageable payloads is more likely to be reliable. It reduces the risk of network failures, timeouts, and other issues when handling large data transfers. Reliability is paramount for mission-critical applications.
Ease of Monitoring and Debugging:
- Smaller payloads are easier to monitor and debug. When issues arise, it's simpler to trace problems and identify their root causes when dealing with smaller, more manageable data sets.
6. Design for failure. Favor availability over consistency.
Your feature flag system should not be able to take down your main application under any circumstance, including network disruptions. Follow these patterns to achieve fault tolerance for your feature flag system.
Zero dependencies: Your application's availability should have zero dependencies on the availability of your feature flag system. Robust feature flag systems avoid relying on real-time flag evaluations because the unavailability of the feature flag system will cause application downtime, outages, degraded performance, or even a complete failure of your application.
Graceful degradation: If the system goes down, it should not disrupt the user experience or cause unexpected behavior. Feature flagging should gracefully degrade in the absence of the Feature Flag Control service, ensuring that users can continue to use the application without disruption.
Resilient Architecture Patterns:
Bootstrapping SDKs with Data: Feature flagging SDKs used within your application should be designed to work with locally cached data, even when the network connection to the Feature Flag Control service is unavailable. The SDKs can bootstrap with the last known feature flag configuration or default values to ensure uninterrupted functionality.
Local Cache: Maintaining a local cache of feature flag configuration helps reduce network round trips and dependency on external services. The local cache can be periodically synchronized with the central Feature Flag Control service when it's available. This approach minimizes the impact of network failures or service downtime on your application.
Evaluate Locally: Whenever possible, the SDKs or application components should be able to evaluate feature flags locally without relying on external services. This ensures that feature flag evaluations continue even when the feature flagging service is temporarily unavailable.
Availability Over Consistency: As the CAP theorem teaches us, in distributed systems, prioritizing availability over strict consistency can be a crucial design choice. This means that, in the face of network partitions or downtime of external services, your application should favor maintaining its availability rather than enforcing perfectly consistent feature flag configuration caches. Eventually consistent systems can tolerate temporary inconsistencies in flag evaluations without compromising availability. In CAP theorem parlance, a feature flagging system should aim for AP over CP.
By implementing these resilient architecture patterns, your feature flagging system can continue to function effectively even in the presence of downtime or network disruptions in the feature flagging service. This ensures that your main application remains stable, available, and resilient to potential issues in the feature flagging infrastructure, ultimately leading to a better user experience and improved reliability.
7. Make feature flags short-lived. Do not confuse flags with application configuration.
Feature flags have a lifecycle shorter than an application lifecycle. The most common use case for feature flags is to protect new functionality. That means that when the roll-out of new functionality is complete, the feature flag should be removed from the code and archived. If there were old code paths that the new functionality replaces, those should also be cleaned up and removed.
Feature flags should not be used for static application configuration. Application configuration is expected to be consistent, long-lived, and read when launching an application. Using feature flags to configure an application can lead to inconsistencies between different instances of the same application. Feature flags, on the other hand, are designed to be short-lived, dynamic, and changed at runtime. They are expected to be read and updated at runtime and favor availability over consistency.
To succeed with feature flags in a large organization, you should:
Use flag expiration dates: By setting expiration dates for your feature flags, you make it easier to keep track of old feature flags that are no longer needed. A proper feature flag solution will inform you about potentially expired flags.
Treat feature flags like technical debt.: You must plan to clean up old feature branches in sprint or project planning, the same way you plan to clean up technical debt in your code. Feature flags add complexity to your code. You’ll need to know what code paths the feature flag enables, and while the feature flag lives, the context of it needs to be maintained and known within the organization. If you don’t clean up feature flags, eventually, you may lose the context surrounding it if enough time passes and/or personnel changes happen. As time passes, you will find it hard to remove flags, or to operate them effectively.
Archive old flags: Feature flags that are no longer in use should be archived after their usage has been removed from the codebase. The archive serves as an important audit log of feature flags that are no longer in use, and allows you to revive them if you need to install an older version of your application.
There are valid exceptions to short-lived feature flags. In general, you should try to limit the amount of long-lived feature flags. Some examples include:
- Kill-switches - these work like an inverted feature flag and are used to gracefully disable part of a system with known weak spots.
- Internal flags used to enable additional debugging, tracing, and metrics at runtime, which are too costly to run all the time. These can be enabled by software engineers while debugging issues.
8. Use unique names across all applications. Enforce naming conventions.
All flags served by the same Feature Flag Control service should have unique names across the entire cluster to avoid inconsistencies and errors.
- Avoid zombies: Uniqueness should be controlled using a global list of feature flag names. This prevents the reuse of old flag names to protect new features. Using old names can lead to accidental exposure of old features, still protected with the same feature flag name.
- Naming convention enforcement: Ideally, unique names are enforced at creation time. In a large organization, it is impossible for all developers to know all flags used. Enforcing a naming convention makes naming easier, ensures consistency, and provides an easy way to check for uniqueness.
Unique naming has the following advantages:
- Flexibility over time: Large enterprise systems are not static. Over time, monoliths are split into microservices, microservices are merged into larger microservices, and applications change responsibility. This means that the way flags are grouped will change over time, and a unique name for the entire organization ensures that you keep the option to reorganize your flags to match the changing needs of your organization.
- Prevent conflicts: If two applications use the same Feature Flag name it can be impossible to know which flag is controlling which applications. This can lead to accidentally flipping the wrong flag, even if they are separated into different namespaces (projects, workspaces etc).
- Easier to manage: It's easier to know what a flag is used for and where it is being used when it has a unique name. E.g. It will be easier to search across multiple code bases to find references for a feature flag when it has a unique identifier across the entire organization.
- Enables collaboration: When a feature flag has a unique name in the organization, it simplifies collaboration across teams, products and applications. It ensures that we all talk about the same feature.
9. Choose open by default. Democratize feature flag access.
Allowing engineers, product owners, and even technical support to have open access to a feature flagging system is essential for effective development, debugging, and decision-making. These groups should have access to the system, along with access to the codebase and visibility into configuration changes:
Debugging and Issue Resolution:
- Code Access: Engineers should have access to the codebase where feature flags are implemented. This access enables them to quickly diagnose and fix issues related to feature flags when they arise. Without code access, debugging becomes cumbersome, and troubleshooting becomes slower, potentially leading to extended downtimes or performance problems.
Visibility into Configuration:
Configuration Transparency: Engineers, product owners, and even technical support should be able to view the feature flag configuration. This transparency provides insights into which features are currently active, what conditions trigger them, and how they impact the application's behavior. It helps understand the system's state and behavior, which is crucial for making informed decisions.
Change History: Access to a history of changes made to feature flags, including who made the changes and when, is invaluable. This audit trail allows teams to track changes to the system's behavior over time. It aids in accountability and can be instrumental in troubleshooting when unexpected behavior arises after a change.
Correlating Changes with Metrics: Engineers and product owners often need to correlate feature flag changes with production application metrics. This correlation helps them understand how feature flags affect user behavior, performance, and system health. It's essential for making data-driven decisions about feature rollouts, optimizations, or rollbacks.
Collaboration:
- Efficient Communication: Open access fosters efficient communication between engineers and the rest of the organization. When it's open by default, everyone can see the feature flagging system and its changes, and have more productive discussions about feature releases, experiments, and their impact on the user experience.
Empowering Product Decisions:
- Product Owner Involvement: Product owners play a critical role in defining feature flags' behavior and rollout strategies based on user needs and business goals. Allowing them to access the feature flagging system empowers them to make real-time decisions about feature releases, rollbacks, or adjustments without depending solely on engineering resources.
Security and Compliance:
- Security Audits: Users of a feature flag system should be part of corporate access control groups such as SSO. Sometimes, additional controls are necessary, such as feature flag approvals using the four-eyes principle.
Access control and visibility into feature flag changes are essential for security and compliance purposes. It helps track and audit who has made changes to the system, which can be crucial in maintaining data integrity and adhering to regulatory requirements.
10. Do no harm. Prioritize consistent user experience.
Feature flagging solutions are indispensable tools in modern software development, enabling teams to manage feature releases and experiment with new functionality. However, one aspect that is absolutely non-negotiable in any feature flag solution is the need to ensure a consistent user experience. This isn't a luxury; it's a fundamental requirement. Feature flagging solutions must prioritize consistency and guarantee the same user experience every time, especially with percentage-based gradual rollouts.
Why Consistency is Paramount:
User Trust: Consistency breeds trust. When users interact with an application, they form expectations about how it behaves. Any sudden deviations can erode trust and lead to a sense of unreliability.
Reduced Friction: Consistency reduces friction. Users shouldn't have to relearn how to use an app every time they open it. A consistent experience reduces the cognitive load on users, enabling them to engage effortlessly.
Quality Assurance: Maintaining a consistent experience makes quality assurance more manageable. It's easier to test and monitor when you have a reliable benchmark for the user experience.
Support and Feedback: Inconsistent experiences lead to confused users, increased support requests, and muddied user feedback. Consistency ensures that user issues are easier to identify and address.
Brand Integrity: A consistent experience reflects positively on your brand. It demonstrates professionalism and commitment to user satisfaction, enhancing your brand's reputation.
Strategies for Consistency in Percentage-Based Gradual Rollouts:
User Hashing: Assign users to consistent groups using a secure hashing algorithm based on unique identifiers like user IDs or emails. This ensures that the same user consistently falls into the same group.
Segmentation Control: Provide controls within the feature flagging tool to allow developers to segment users logically. For instance, segment by location, subscription type, or any relevant criteria to ensure similar user experiences.
Fallback Mechanisms: Include fallback mechanisms in your architecture. If a user encounters issues or inconsistencies, the system can automatically switch them to a stable version or feature state.
Logging and Monitoring: Implement robust logging and monitoring. Continuously track which users are in which groups and what version of the feature they are experiencing. Monitor for anomalies or deviations and consider building automated processes to disable features that may be misbehaving.
Transparent Communication: Clearly communicate the gradual rollout to users. Use in-app notifications, tooltips, or changelogs to inform users about changes, ensuring they know what to expect.
In summary, consistency is a cornerstone of effective feature flagging solutions. When designing an architecture for percentage-based gradual rollouts, prioritize mechanisms that guarantee the same user gets the same experience every time. This isn't just about good software practice; it's about respecting your users and upholding their trust in your application. By implementing these strategies, you can create a feature flagging solution that empowers your development process and delights your users with a dependable and consistent experience.
11. Enable traceability. Make it easy to understand flag evaluation.
Developer experience is a critical factor to consider when implementing a feature flag solution. A positive developer experience enhances the efficiency of the development process and contributes to the overall success and effectiveness of feature flagging. One crucial aspect of developer experience is ensuring the testability of the SDK and providing tools for developers to understand how and why feature flags are evaluated. This is important because:
Ease of Testing and Debugging:
Faster Development Cycles: A feature flagging solution with a testable SDK allows developers to quickly test and iterate on new features. They can easily turn flags on or off, simulate different conditions, and observe the results without needing extensive code changes or redeployments.
Rapid Issue Resolution: When issues or unexpected behavior arise, a testable SDK enables developers to pinpoint the problem more efficiently. They can examine the flag configurations, log feature flag decisions, and troubleshoot issues more precisely.
Visibility into Flag Behaviour:
Understanding User Experience: Developers need tools to see and understand how feature flags affect the user experience. This visibility helps them gauge the impact of flag changes and make informed decisions about when to roll out features to different user segments. Debugging a feature flag with multiple inputs simultaneously makes it easy for developers to compare the results and quickly figure out how a feature flag evaluates in different scenarios with multiple input values.
Enhanced Collaboration: Feature flagging often involves cross-functional teams, including developers, product managers, and QA testers. Providing tools with a clear view of flag behavior fosters effective collaboration and communication among team members.
Transparency and Confidence:
Confidence in Flag Decisions: A transparent feature flagging solution empowers developers to make data-driven decisions. They can see why a particular flag evaluates to a certain value, which is crucial for making informed choices about feature rollouts and experimentation.
Reduced Risk: When developers clearly understand of why flags evaluate the way they do, they are less likely to make unintentional mistakes that could lead to unexpected issues in production.
Effective Monitoring and Metrics:
Tracking Performance: A testable SDK should provide developers with the ability to monitor the performance of feature flags in real time. This includes tracking metrics related to flag evaluations, user engagement, and the impact of flag changes.
Data-Driven Decisions: Developers can use this data to evaluate the success of new features, conduct A/B tests, and make informed decisions about optimizations.
Usage metrics: A feature flag system should provide insight on an aggregated level about the usage of feature flags. This is helpful for developers so that they can easily assess that everything works as expected.
Documentation and Training:
- Onboarding and Training: The entire feature flag solution, including API, UI, and the SDKs, requires clear and comprehensive documentation, along with easy-to-understand examples, in order to simplify the onboarding process for new developers. It also supports the ongoing training of new team members, ensuring that everyone can effectively use the feature flagging solution.
Thank you for reading